이미지 크롤링
이미지 크롤링은 Object Detection을 위한 학습에 필요한 과정입니다.
특정 객체를 학습 시키기 위해선 많은 이미지들이 필요하고 이를 일일이 다운 받기엔 너무 많은 시간이 듭니다.
이를 자동화하기 위해 파이썬 기반 이미지 크롤링 프로그램을 만들어 보겠습니다.
Selenium을 이용한 네이버 이미지 크롤링
네이버에서는 빠른 검색을 위해 한 번에 50장의 사진을 불러오고 스크롤을 다 내리면 다시 50장을 불러오는 형식을 취하고 있습니다.
이는 이미지 크롤링에 악영향을 끼치고 이를 해결하기 위해 자동으로 스크롤바를 내려주는 기능이 필요합니다.
이 기능을 Selenium을 통해 구현하겠습니다.
제 컴퓨터의 환경은 윈도우7 64bit Jupyter Notbook(파이썬3)입니다.
우선 Anaconda prompt에 다음과 같은 명령어를 입력해줍니다.
pip install selenium
다음은 google Chrome Driver를 설치해주어야 합니다.
https://sites.google.com/a/chromium.org/chromedriver/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
sites.google.com
이 사이트에 들어가셔서 자기의 chrome과 맞는 버젼을 자기가 알수있는 경로에 다운받아야 합니다.
chrome의 버젼은 시작>제어판>프로그램 및 기능>chrome의 버젼 항목에서 알 수 있습니다.
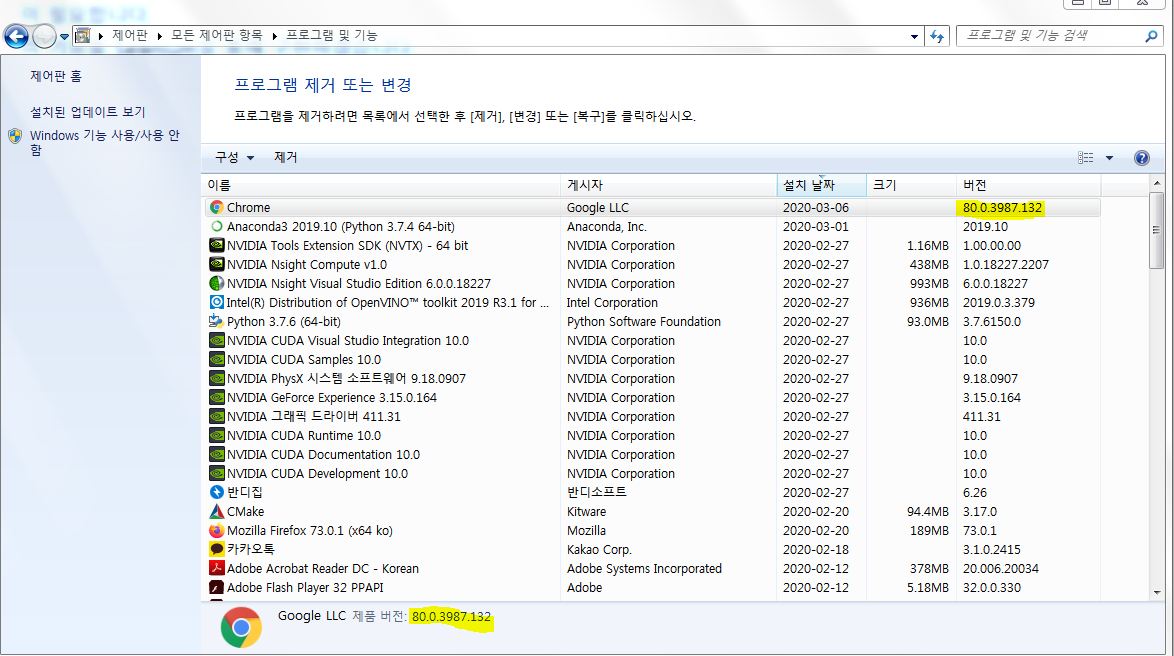
알맞는 버젼을 자기가 알 수 있는 경로에 다운받아 줍니다. 저는
'C:/Users/Administrator/Documents/chromedriver_win32/chromedriver' 에 다운받아 주었습니다.
여기까지 진행하셨으면 기본 세팅은 끝났습니다.
다음은 코드를 구현하겠습니다.
1. 원하는 검색어로 브라우저 열기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from selenium import webdriver
import requests as req
import time
from selenium.webdriver.common.keys import Keys
from urllib.request import urlopen
import os
#찾고자 하는 검색어를 url로 만들어 준다.
searchterm = 'car'
url = "https://search.naver.com/search.naver?where=image§ion=image&query="+searchterm
#chrome 사용
browser = webdriver.Chrome('C:/Users/Administrator/Documents/chromedriver_win32/chromedriver')
#오류 방지를 위한 시간 간격 두기
browser.implicitly_wait(3)
#해당 검색어로 브라우져를 오픈해준다.
browser.get(url)
time.sleep(1)
# 이미지를 불러오기 위해 가로 = 0, 세로 = 30000 픽셀 스크롤한다.
for _ in range(10000):
browser.execute_script("window.scrollBy(0,30000)")
|
cs |
chromedrive를 통해 chrome을 열고 selenium을 통해 자동으로 스크롤을 내려줍니다.
2. 저장 전 사전 설정
|
1
2
3
4
5
6
7
8
9
|
count = 0
photo_list = [] #다운 받을 사진의 list 생성
#span태그의 img_border클래스를 가져옴
photo_list = browser.find_elements_by_tag_name("span.img_border")
# 소스코드가 있는 경로에 '검색어' 폴더가 없으면 만들어준다.(이미지 저장 폴더를 위해서)
if not os.path.exists(searchterm):
os.mkdir(searchterm)
|
cs |
네이버의 사진은 span.img_border class에 있습니다. 이를 통해 이미지를 불러오고 사진의 이름을 폴더로 만들어 그 폴더에 사진을 저장 시켜줍니다
3. 이미지 저장
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
for index, img in enumerate(photo_list[0:]):
#태그의 리스트를 하나씩 클릭한다.
img.click()
#확대된 이미지의 정보는 img태그의 _image_source라는 class안에 담겨있다.
html_objects = browser.find_element_by_tag_name('img._image_source')
current_src = html_objects.get_attribute('src')
t = urlopen(current_src).read()
if index < 400 : #다운 받을 장 수 정하기
filename = searchterm+str(count)+".jpg"
File = open(os.path.join(searchterm , searchterm + "_" + str(count) + ".jpg"), "wb")
File.write(t)
count += 1
print("img save"+str(count))
else:
print("end")
browser.close()
break
|
cs |
for문을 돌며 네이버의 사진 block을 하나하나 클릭하고 사용자가 지정한 사진의 갯수만큼 다운을 받습니다.
4. 완성된 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
from selenium import webdriver
import requests as req
import time
from selenium.webdriver.common.keys import Keys
from urllib.request import urlopen
import os
#찾고자 하는 검색어를 url로 만들어 준다.
searchterm = '자동차'
#경로 + 검색어
url = "https://search.naver.com/search.naver?where=image§ion=image&query="+searchterm
#브라우저를 크롬으로 만들어주고 인스턴스를 생성해준다.
browser = webdriver.Chrome('C:/Users/Administrator/Documents/chromedriver_win32/chromedriver')
#브라우저를 오픈할 때 시간간격을 준다.
browser.implicitly_wait(3)
#해당 경로로 브라우져를 오픈해준다.
browser.get(url)
time.sleep(1)
for _ in range(10000):
# 가로 = 0, 세로 = 30000 픽셀 스크롤한다.
browser.execute_script("window.scrollBy(0,30000)")
count = 0
photo_list = []
#span태그의 img_border클래스를 가져옴
photo_list = browser.find_elements_by_tag_name("span.img_border")
# 소스코드가 있는 경로에 '검색어' 폴더가 없으면 만들어준다.(이미지 저장 폴더를 위해서)
if not os.path.exists(searchterm):
os.mkdir(searchterm)
for index, img in enumerate(photo_list[0:]):
#위의 큰 이미지를 구하기 위해 위의 태그의 리스트를 하나씩 클릭한다.
img.click()
#확대된 이미지의 정보는 img태그의 _image_source라는 class안에 담겨있다.
html_objects = browser.find_element_by_tag_name('img._image_source')
current_src = html_objects.get_attribute('src')
t = urlopen(current_src).read()
if index < 400 : #40
filename = searchterm+str(count)+".jpg"
File = open(os.path.join(searchterm , searchterm + "_" + str(count) + ".jpg"), "wb")
File.write(t)
count += 1
#before_src = current_src 조금 더 고민
#current_src = ""
print("img save"+str(count))
else:
print("저장 성공")
browser.close()
break
|
cs |
5. 문제점
이 프로그램은 icrawler나 beautiful soup와는 다르게 사용자가 입력한 숫자만큼의 사진을 모두 다운 받습니다.
하지만 아무리 좋은 검색 엔진이여도 1000장의 사진을 검색하면 그 중 30%정도는 원하는 사진이 아닐 경우가 있습니다. 네이버에서 하는 검색 또한 그러하며 많은 이미지 크롤링을 위해선 다양한 검색 엔진에서 사진을 다운받아야 합니다.
다음엔 구글, bing, Baidu에서 이미지를 다운 받을 수 있는 icrawler에 대해서 포스팅 하겠습니다.
'Object Dectect' 카테고리의 다른 글
| Yolo_Mark를 통한 학습 데이터 만들기1(Darknet) (9) | 2020.03.02 |
|---|---|
| Jupyter Notebook에서 OpenCV 설치, 사용하기(python) (2) | 2020.02.27 |
| Visual Studio에서 OpenCV 설치, 사용하기(C/C++) (1) | 2020.02.27 |



댓글